


What Is A/B Testing for Websites and How Do You Do It Right?
By Josh Ternyak

March 29, 2026
A/B testing is how the best websites get better over time — systematically, based on evidence rather than opinions. This guide covers what it is, how it works, what to test, and how to avoid the mistakes that produce meaningless results.
The Method That Replaces Opinions with Evidence
Every team that manages a website has opinions. The founder thinks the headline should be more benefit-focused. The designer thinks the button should be larger. The marketing manager thinks the CTA copy should say "Get Started" instead of "Contact Us." The developer thinks the page loads fast enough. Everyone has a different view on what would improve performance.
And everyone might be wrong.
A/B testing is the method that converts these opinions into evidence. Instead of debating what might work, you show different versions of an element to different visitors simultaneously and measure which version actually produces better outcomes. The data decides. Opinions are inputs to the hypothesis; they're not the conclusion.
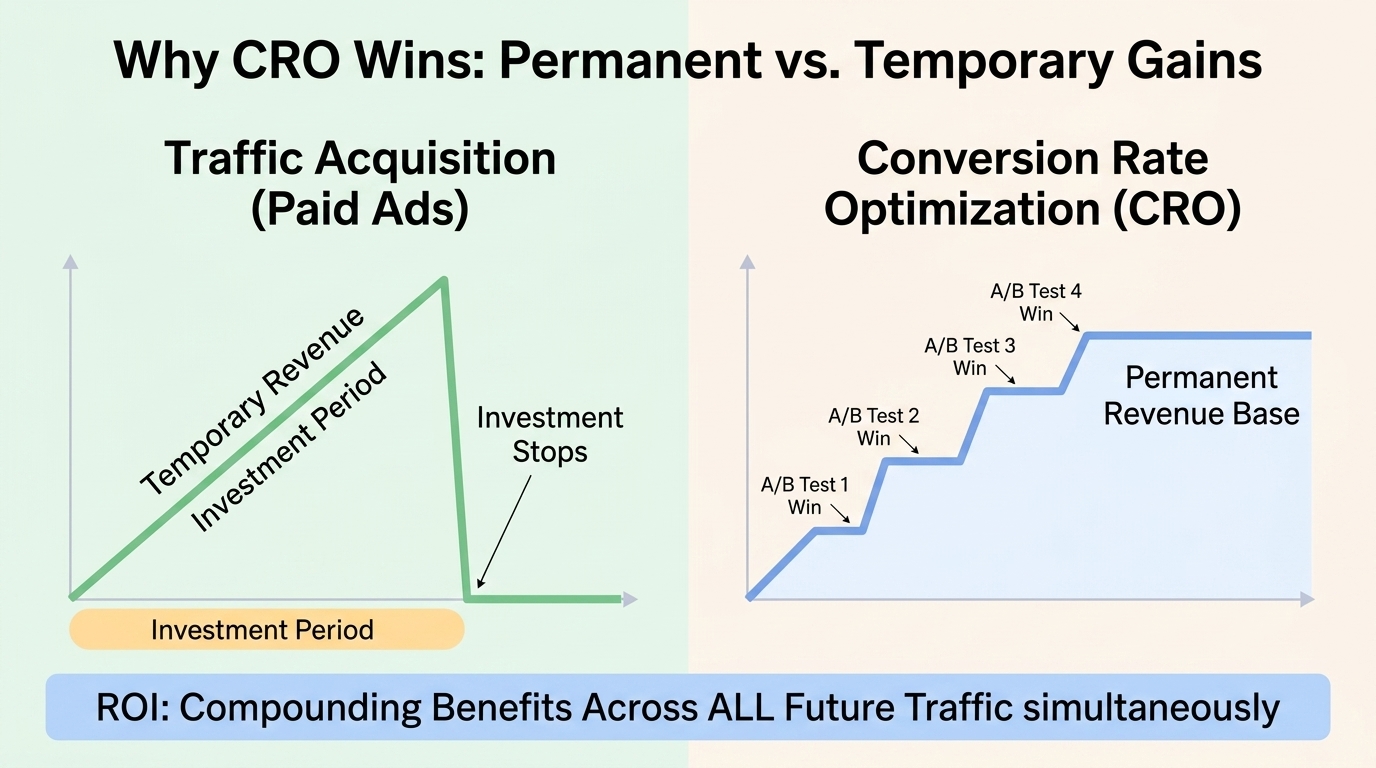
The companies that use A/B testing systematically — Amazon, Google, Facebook, Booking.com — run thousands of tests simultaneously, year-round. Booking.com has been known to run 1,000+ concurrent tests. Not because every individual test produces a big win, but because dozens of small, validated improvements compounding over time produce a dramatically better-converting product than any amount of intuition-driven design could achieve.
This guide covers what A/B testing is, the statistical mechanics that make it valid (or invalid), what to test, how to run tests correctly, and the common mistakes that produce misleading results.
What A/B Testing Is
A/B testing (also called split testing) is a controlled experiment in which two versions of a web page, email, or other asset are shown to different segments of users simultaneously to determine which version drives a desired outcome at a higher rate.
Version A (the control) is typically the current version. Version B (the variant) is the modified version with one specific element changed. Traffic is split randomly between the two versions — some visitors see A, some see B. The split is typically 50/50, though it can be adjusted (90/10 for lower-risk testing of more aggressive changes).
The test runs until statistical significance is achieved — until there's enough data to determine with confidence that the observed difference in conversion rates isn't due to random chance. At that point, the winning version becomes the new control, and the cycle begins again with a new hypothesis.
A/B testing is distinct from:
Multivariate testing: Testing multiple elements simultaneously (headline + image + CTA button all changed at once), where the goal is finding the best combination. Requires much more traffic to achieve significance and is harder to interpret because multiple variables change simultaneously. Usually reserved for high-traffic pages where the interaction effects between elements are worth understanding.
User testing: Watching individual users navigate the site and gathering qualitative feedback. User testing reveals why things happen; A/B testing reveals what performs better at scale. Both are valuable; they answer different questions.
Before/after analysis: Comparing metrics before and after a change. Invalid as a test because you can't control for changes in traffic quality, seasonality, or external factors that might have caused the metric change. Always test simultaneously, not sequentially.
The Statistics Behind Why A/B Testing Works (and When It Doesn't)
A/B testing produces valid results only when executed with statistical rigor. Understanding the basic mechanics prevents the most common mistakes:
Statistical Significance
Statistical significance is the confidence threshold at which you can conclude that the observed difference between variants is unlikely to be due to chance. The standard threshold is 95% confidence — meaning there's only a 5% probability that the observed difference would occur if there were actually no true difference between the versions.
Why 95%? Because at that threshold, you'll incorrectly declare a winner from random noise about 1 in 20 tests. Higher thresholds (99%) reduce false positives but require more traffic to reach. Lower thresholds (90%) require less traffic but produce more false conclusions.
Most A/B testing tools calculate statistical significance automatically and display it as a percentage or p-value. Wait until your tool shows 95%+ confidence before declaring a winner. Not 70%. Not 80%. 95%.
Sample Size and Statistical Power
The minimum sample size needed to detect a real difference depends on: your current conversion rate, the minimum effect size you want to be able to detect, and your significance threshold. Smaller expected improvements require larger sample sizes to detect reliably.
A/B testing calculators (Evan Miller's sample size calculator at evanmiller.org/ab-testing/sample-size.html is the standard reference) let you input your baseline conversion rate and expected improvement to calculate the minimum sample size needed.
Example: if your current conversion rate is 3% and you want to detect a 20% relative improvement (3% → 3.6%), you need approximately 15,000 visitors per variant — 30,000 total — to detect this reliably with 80% statistical power at 95% confidence.
The practical implication: pages with low conversion rates or low traffic volumes require very long test durations to reach significance. A page with 50 conversions per month would need many months to validly test a 20% improvement. Don't run A/B tests on low-traffic pages expecting reliable results in days or weeks.
Peeking and Early Stopping
The temptation: run a test for a few days, see that variant B is converting at 8% versus variant A's 6%, and stop the test to implement B.
The problem: peeking at running tests and stopping early when one variant appears to be winning is statistically invalid. Due to random variation, early test results fluctuate significantly. A variant that appears to be winning at 50% confidence after a few days frequently turns out to be indistinguishable from the control when the test runs to proper significance.
The solution: decide your sample size or test duration before the test begins, and run to that endpoint regardless of interim results. Many A/B testing tools implement "sequential testing" or "always valid inference" statistical methods that allow valid early stopping — check your tool's documentation for whether early stopping is statistically valid given its methodology.
Novelty Effect
Visitors who have previously seen Version A may behave differently toward Version B simply because it's different — the novelty drives engagement that isn't representative of long-term behavior. This can produce false positive results where a variant appears to win because of novelty rather than genuine improvement.
Mitigation: run tests long enough to include multiple sessions from the same users. Avoid ending tests based solely on the first few days of data. For significant changes, run the test for at least 2–4 weeks to let novelty effects diminish.
What to Test: The High-Impact Elements
Not everything is worth testing. The highest ROI tests focus on elements that:
- Appear on high-traffic pages (more exposure = faster statistical significance)
- Directly influence the conversion action you're measuring
- Have significant room for improvement (a mediocre headline has more potential upside than an already-excellent one)
- Are based on a hypothesis grounded in user research (evidence of a problem to solve)
Headlines
The most consistently high-impact element to test. Headlines determine in the first 3 seconds whether a visitor stays or leaves. Even small improvements in headline clarity or specificity produce meaningful conversion rate differences.
What to test in headlines: value proposition framing (outcome-focused vs. feature-focused), specificity level (general vs. specific), audience acknowledgment (with "for [specific audience]" vs. without), urgency framing, question vs. statement format.
CTA Copy and Button Text
CTA copy is consistently one of the highest-impact, easiest tests on any conversion-focused page. "Get Started" vs. "Start My Free Trial" vs. "Try It Free." "Contact Us" vs. "Get a Free Quote" vs. "Talk to an Expert." Even small copy changes on primary CTAs produce measurable conversion differences.
The general finding across thousands of CTA tests: specific beats generic, outcome-focused beats action-focused, first-person beats second-person ("Get My Quote" beats "Get Your Quote").
CTA Placement and Prominence
Where the CTA appears on the page, its size, and its visual prominence all affect click rates. Above the fold vs. below. Full-width vs. inline. Contrasting color vs. matching brand color. Sticky vs. static.
Hero Image or Video
The hero visual is the most viewed element above the fold. Testing different image types (product screenshots vs. lifestyle photography vs. illustrations), human vs. non-human imagery, and image presence vs. absence produces meaningful conversion insights on many pages.
Social Proof Placement and Format
Testing where testimonials, ratings, and review counts appear (above the fold vs. below, adjacent to CTA vs. separate section), how they're formatted (quote vs. video vs. star rating), and which specific testimonials are shown.
Pricing Presentation
For e-commerce and SaaS: price anchoring (showing the highest plan first vs. recommended plan first), pricing table formats, free trial vs. free tier vs. money-back guarantee framing, annual vs. monthly pricing default.
Form Length and Fields
The research is consistent: fewer form fields produce higher completion rates. Testing removing each field individually (with the business impact of losing that data evaluated separately) is among the highest-impact conversion tests available for lead generation pages.
Page Length
Long vs. short versions of landing pages. For some audiences and offers, comprehensive long pages convert better (more objection handling, more social proof). For others, concise pages convert better (reduces overwhelm, faster path to conversion). The right answer depends on the audience and offer — test both.
The A/B Testing Process
Step 1: Research, Not Guessing
The best A/B tests start with evidence of a problem, not a whim. Before forming a hypothesis: review your analytics for pages with conversion issues, watch session recordings of non-converting visitors, run heatmaps to see where visitors click and scroll, and review user feedback or survey data about objections.
A hypothesis based on evidence: "We believe the contact form completion rate is low because visitors hesitate on the 'Phone Number' field (session recordings show many users completing the form and abandoning at that field). We'll test removing the phone number field to see if completion rate improves."
This is more actionable and more likely to produce a significant result than: "We think changing the button color might help."
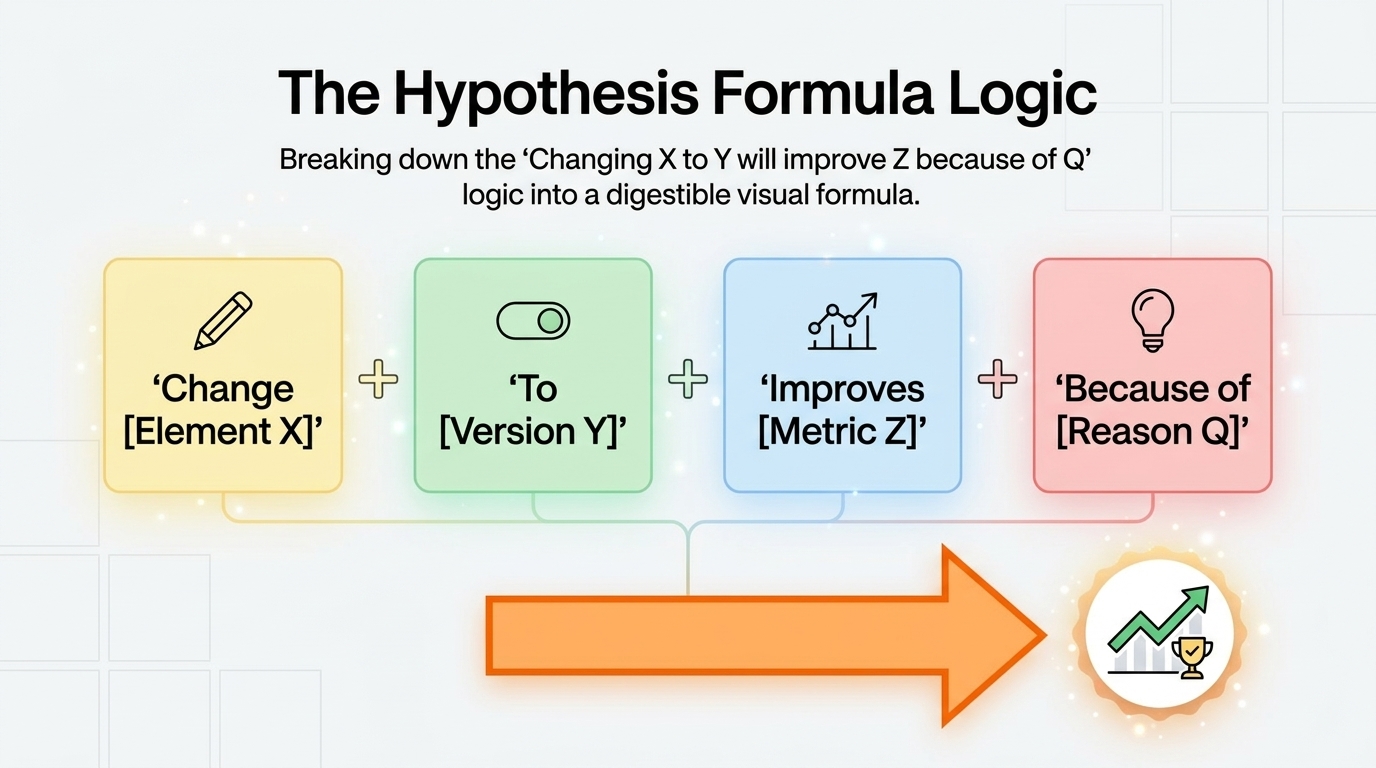
Step 2: Form a Specific Hypothesis
A well-structured hypothesis: "We believe that [changing X to Y] will [increase/decrease] [metric] because [evidence/reasoning]."
The hypothesis defines the change, the expected direction, and the justification. This structure forces clarity about what you're trying to learn and prevents post-hoc rationalization of results that don't go as expected.
Step 3: Define Success Metrics
Before running the test, define: what metric is the primary success measure, and what metrics are secondary indicators you'll monitor. Primary metric should be the direct conversion event — form submission, purchase, signup. Secondary metrics might include click-through rate on other elements, pages per session, or time on page.
Selecting the primary metric after seeing results is p-hacking — a form of statistical manipulation that produces misleading conclusions.
Step 4: Calculate Required Sample Size
Using a sample size calculator, determine how many visitors each variant needs before the test can validly conclude. Set this as your minimum test duration.
Step 5: Implement and Launch
Implement the variant with your chosen A/B testing tool. Verify the test is splitting traffic correctly and both versions render as intended. Launch during a representative period — not during a major holiday, not the week of a big promotion that will change the traffic mix.
Step 6: Monitor for Technical Issues
During the first 24 hours, monitor: are both variants loading correctly? Is traffic splitting as expected? Are conversion events being tracked for both variants? Technical issues in the first hours can corrupt the entire dataset.
Step 7: Wait for Significance
Don't stop the test early. Don't peek at results and make decisions at low confidence. Run to the predetermined sample size or until your tool shows 95%+ significance, whichever comes later.
Step 8: Analyze and Decide
At significance: if the variant wins, implement it as the new baseline. If the control wins (the variant performed worse), the hypothesis was wrong but you've learned something valuable — document why you think it didn't work. If results are inconclusive, the effect is likely smaller than your test was powered to detect — run a longer test or accept the inconclusive result.
Step 9: Document and Iterate
Document every test: hypothesis, variants, results, statistical confidence, and learnings. This repository of testing history prevents re-testing things that already have answers and builds institutional knowledge about what resonates with your audience.
A/B Testing Tools
Google Optimize (deprecated): Google's free A/B testing tool has been sunset as of 2023. It's no longer available.
VWO ($200+/month): Comprehensive testing platform with visual editor, heatmaps, session recordings, and enterprise-grade analysis. The industry standard for mid-size to enterprise testing programs.
Optimizely ($1,000+/month): Enterprise-grade experimentation platform. Sophisticated statistical analysis, feature flags, and full-stack testing capabilities. Used by major digital businesses running high-volume testing programs.
AB Tasty ($500+/month): Mid-market testing and personalization platform with good UX and reasonable pricing for smaller teams.
Convert ($699+/month): Privacy-focused testing platform with good statistical rigor and competitive pricing for smaller programs.
For landing page-specific testing: Unbounce, Instapage, and Leadpages all have built-in A/B testing for their respective landing page builders.
The Bottom Line
A/B testing is the method that systematically replaces opinions with evidence in website optimization. It works by exposing different visitors to different versions of an element simultaneously and measuring which version produces better outcomes — with statistical rigor that distinguishes genuine improvement from random noise.
Done correctly, with research-grounded hypotheses, proper sample sizes, valid statistical analysis, and systematic documentation, A/B testing compounds into a significant conversion advantage over time. The sites with the highest conversion rates aren't those that were designed best at launch — they're those that have been tested and improved most systematically over time.
Start with the highest-traffic, highest-impact page on your site. Form a hypothesis based on user research, not intuition. Run the test to statistical significance. Implement the winner. Repeat indefinitely.
At Scalify, we build websites with conversion optimization built into the foundation — clean, testable layouts, measurable conversion events, and analytics configured from launch so your A/B testing program has a solid baseline to start improving from day one.


















.jpeg)

.jpeg)











78 SW 7th St, Miami, FL 33130


