


What Is Robots.txt and How Should You Configure It?
By Josh Ternyak

April 1, 2026
Comprehensive 2026 guide: What Is Robots.txt and How Should You Configure It?
The Tiny File That Controls What Google Can and Cannot See
There exists a text file that, if misconfigured, can make your entire website invisible to Google overnight. It's not hidden deep in your server configuration. It's not encrypted or complex. It's a plain text file, often just a few lines long, sitting at the very root of your domain where any browser can read it by navigating to yoursite.com/robots.txt.
That file is robots.txt, and while it sounds modest — a small configuration file that search engines check before crawling — its implications for a website's search visibility are significant. A single misplaced "Disallow: /" line in a staging configuration that accidentally makes it to production has cost businesses weeks of lost organic traffic before being discovered.
Understanding robots.txt — what it does, what it doesn't do, and how to configure it correctly — is one of the most fundamental technical SEO skills any website manager can have.
What Robots.txt Is
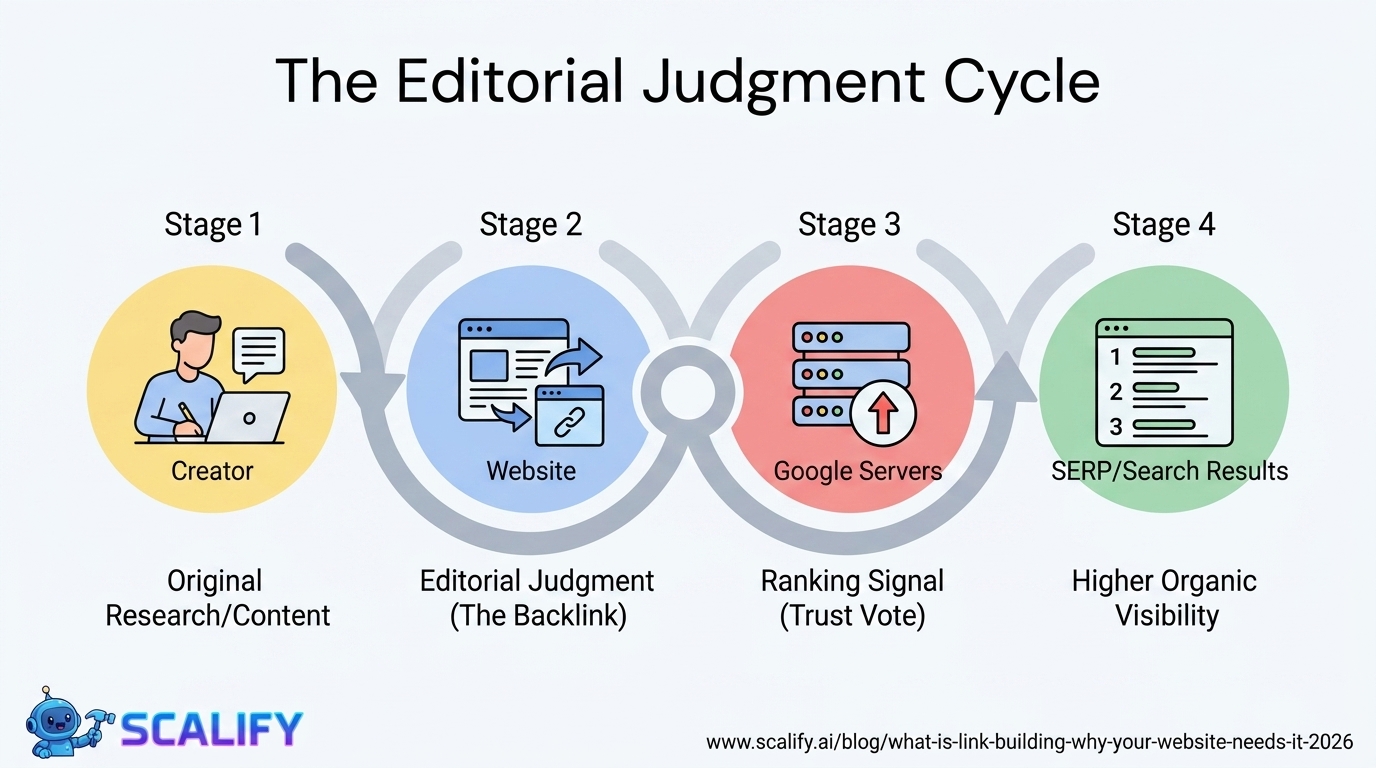
Robots.txt is a plain text file that website owners use to communicate instructions to web crawlers about which parts of the site they're allowed to access. It lives at the root of your domain — always accessible at yoursite.com/robots.txt — and follows the Robots Exclusion Protocol, a standard that web crawlers are designed to respect.
When a well-behaved web crawler (like Googlebot) visits your website, it first checks your robots.txt file before crawling anything. It reads the instructions and determines which URLs it's allowed to crawl based on those instructions. If robots.txt says "you can crawl everything," the crawler proceeds normally. If it says "don't crawl these specific directories," the crawler respects those restrictions.
The crucial distinction: robots.txt controls crawling, not indexing. These are different things:
Crawling is when Google's bot visits a URL to read its content.
Indexing is when Google adds a URL to its search index so it can appear in search results.
A URL blocked by robots.txt will not be crawled — but it might still be indexed if Google discovers its existence from links on other pages. Google can index a URL without crawling it, showing it in search results with limited information. To prevent a page from appearing in search results at all, you need a noindex meta tag or header (which requires crawling to discover), not robots.txt.
This is why "blocking pages with robots.txt to prevent them from ranking" is a misunderstanding — and why a URL blocked by robots.txt can still show up in Google search, just without a rich snippet.
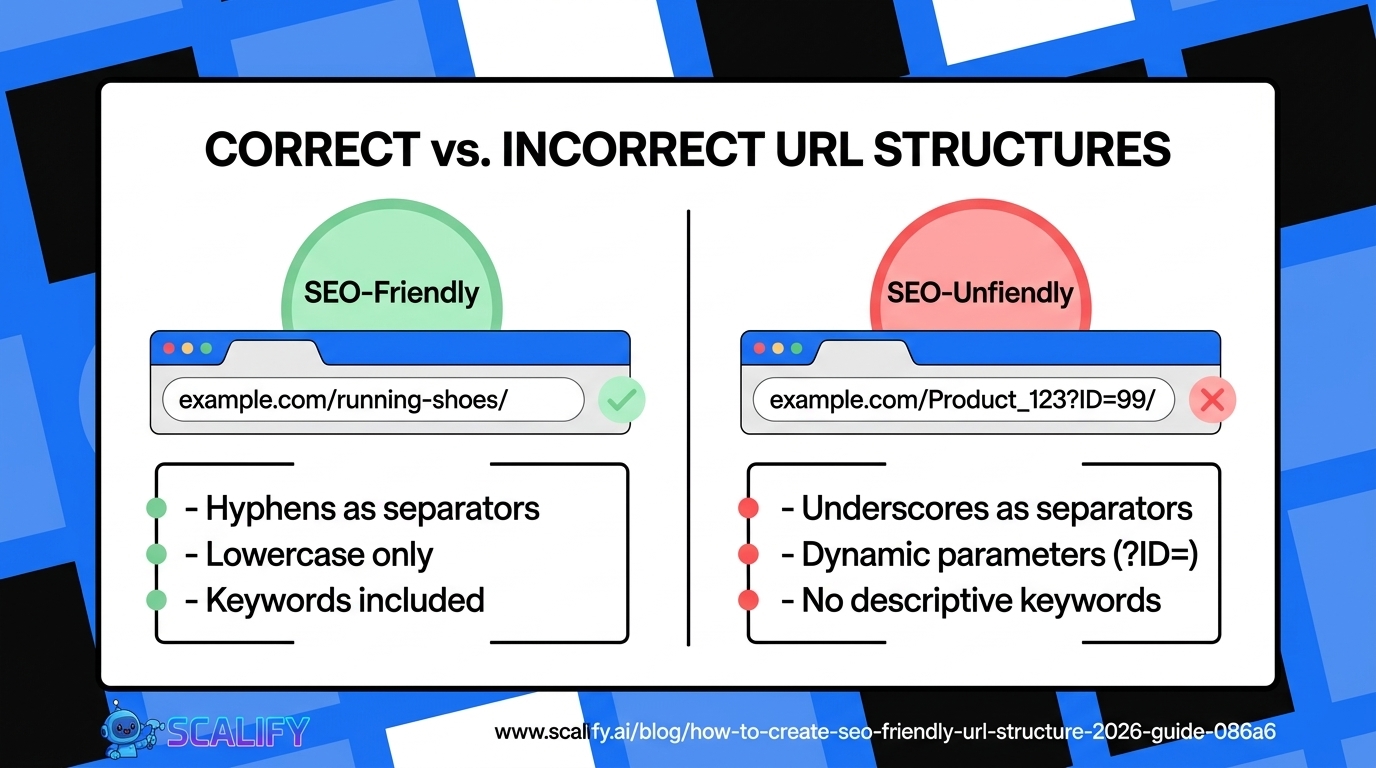
The Robots.txt Syntax
A robots.txt file consists of groups of directives, each applying to one or more user agents (crawlers). The basic structure:
User-agent: [crawler name]
Disallow: [URL path not to crawl]
Allow: [URL path that is allowed]A simple example:
User-agent: *
Disallow: /admin/
Disallow: /private/
Allow: /
Sitemap: https://yoursite.com/sitemap.xmlBreaking this down:
User-agent: * — The asterisk is a wildcard meaning "all crawlers." You can specify specific crawlers by name (User-agent: Googlebot, User-agent: Bingbot) to apply different rules to different crawlers, but most robots.txt files use the wildcard to apply rules universally.
Disallow: /admin/ — Don't crawl any URL that starts with /admin/. The Disallow directive takes a URL path (not a full URL). Everything under /admin/ — /admin/login, /admin/users, /admin/settings — is blocked.
Disallow: /private/ — Don't crawl URLs under /private/.
Allow: / — Allow crawling of the root and everything that isn't specifically disallowed. This directive is technically redundant if everything not disallowed is allowed by default — but it's sometimes used for clarity or to override a broader Disallow with an exception.
Sitemap: — Not part of the Robots Exclusion Protocol originally, but widely supported. Points crawlers directly to your XML sitemap location. A good practice to include.
The Most Important Rules
Disallow: / — The Most Dangerous Line in SEO
Disallow: / means "don't crawl anything on this entire site." A single forward slash with nothing after it matches every URL — the homepage, every page, every asset, everything.
This line is correct and appropriate in robots.txt for staging environments. It ensures Googlebot doesn't index your staging site, which would create duplicate content with your production site.
This line deployed to production is catastrophic. It tells Google to not crawl any page on your website. Within weeks, pages that were previously indexed begin dropping from search results as Google re-crawls them and receives the disallow instruction. Traffic drops. The business problem is severe. Finding the cause requires someone to check robots.txt — which is often the last place people look when traffic drops.
This is not a hypothetical. It has happened to major websites. Checking your production robots.txt file — navigating to yoursite.com/robots.txt in a browser — should be part of any website launch checklist and any post-deployment verification process.
Disallow: Blocks Crawling, Not Indexing
If you want to prevent a page from being crawled AND indexed, use a noindex meta tag rather than robots.txt. The noindex tag requires crawling to read — so if you use robots.txt to block crawling AND add a noindex tag, the noindex tag can't be read because Google's crawler is blocked from accessing the page.
For truly sensitive pages that you don't want indexed: use noindex meta tags without blocking in robots.txt. For pages where you genuinely don't need Google to crawl (and don't care if they're occasionally indexed from external links): robots.txt blocking is appropriate.
Crawling Is Still Possible for Blocked URLs
Well-behaved crawlers like Googlebot respect robots.txt. But robots.txt is a voluntary protocol — it requests, rather than enforces, compliance. Malicious bots, scrapers, and badly configured crawlers may ignore robots.txt instructions. For genuinely sensitive content, server-level access controls (authentication, IP restrictions) are the appropriate security mechanism — not robots.txt.
What to Include in Robots.txt
The appropriate content of robots.txt depends on your site. Some general guidelines:
For Most Small Business Websites
The robots.txt for a typical small business brochure site, e-commerce store, or blog is very simple:
User-agent: *
Disallow:
Sitemap: https://yoursite.com/sitemap.xmlAn empty Disallow directive (no path after it) means "nothing is disallowed" — allow everything. This simple robots.txt tells crawlers they're welcome everywhere and provides the sitemap location. Simple and effective for sites without sections that need crawl exclusion.
For WordPress Sites
WordPress has specific paths worth blocking to avoid wasting crawl budget on non-content pages:
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-includes/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://yoursite.com/sitemap.xmlwp-admin is the WordPress administration area — no public content there that Google needs to crawl. wp-includes contains WordPress system files. admin-ajax.php is allowed explicitly because some front-end functionality (forms, dynamic content) may use it.
For E-Commerce Sites
E-commerce sites may want to block faceted navigation URLs (URLs created by filters and sorting that produce near-duplicate content), cart and checkout pages, and internal search results:
User-agent: *
Disallow: /cart
Disallow: /checkout
Disallow: /account
Disallow: /search
Disallow: /?sort=
Disallow: /?filter=
Sitemap: https://yoursite.com/sitemap.xmlThe faceted navigation URLs (?sort= and ?filter= parameters) can produce thousands of near-duplicate pages that waste crawl budget without providing unique indexable content. Blocking them keeps Google's crawl focused on your actual product pages.
For Sites with API Endpoints or Non-Public Directories
User-agent: *
Disallow: /api/
Disallow: /staging/
Disallow: /internal/
Disallow: /uploads/
Sitemap: https://yoursite.com/sitemap.xmlVerifying and Testing Your Robots.txt
Reading Your Current Robots.txt
Navigate to yoursite.com/robots.txt in any browser. The file should display as plain text. If you get a 404 error, no robots.txt exists (which is fine — the default without robots.txt is to allow all crawling). If you see a robots.txt file, read it carefully.
Google's Robots.txt Tester
Google Search Console provides a robots.txt tester (under Settings → robots.txt → Open Inspector, or navigate to the old GSC tools URL). This tool shows your current robots.txt content, validates its syntax, and allows you to test specific URLs to see whether they would be blocked by the current robots.txt configuration.
Use this to verify: are important pages blocked? Are admin pages properly blocked? Is the syntax valid with no errors?
URL Inspection Tool
Google Search Console's URL Inspection tool shows you whether a specific URL is blocked by robots.txt. Inspect any important URL and check whether "Google can access URL" shows a robots.txt block.
Robots.txt and Different Search Engines
Most major search engines respect robots.txt: Google (Googlebot), Bing (Bingbot), Yahoo (which uses Bing's crawlers), DuckDuckGo (which uses Bing and other sources).
Specific directives can target specific crawlers:
User-agent: Googlebot
Disallow: /no-google/
User-agent: Bingbot
Disallow: /no-bing/
User-agent: *
Disallow: /admin/This targeted control is rarely necessary for typical sites. Most robots.txt files use the wildcard User-agent to apply rules universally.
Robots.txt vs. Noindex Meta Tag: Choosing the Right Tool
The confusion between robots.txt and noindex tags is common enough to address directly:
Use robots.txt Disallow when:
- You genuinely don't want Google to crawl URLs (saves crawl budget)
- The pages have no content Google could index (admin pages, API endpoints)
- You're blocking a staging environment
- You're blocking parameter-based URLs that create duplicate content
Use noindex meta tag when:
- You want Google to crawl the page (to discover its noindex status) but not include it in search results
- You have pages that should be accessible to visitors but not searchable (thank-you pages, internal resource pages, duplicate content pages you can't remove)
- You're managing which version of a page appears in search for duplicate/similar content situations
Don't use both on the same page: If robots.txt blocks crawling of a page that has a noindex tag, the noindex tag can never be read (Googlebot is blocked from accessing the page). If you want noindex to work, the page must be crawlable.
Robots.txt for Security: What It Can't Do
A common misconception: robots.txt protects sensitive content from search engines. It doesn't. Robots.txt is a public file — anyone can read it by navigating to yoursite.com/robots.txt. Ironically, listing sensitive directories in robots.txt can actually advertise their existence to people looking for things to exploit.
Security-sensitive paths (admin interfaces, internal documentation, confidential data) should be protected by authentication, IP restrictions, or server-level access controls — not robots.txt. Robots.txt controls well-behaved crawlers; it does nothing to restrict unauthorized human access.
The Bottom Line
Robots.txt is a simple, important file that controls what search engine crawlers can access on your website. For most sites, a simple robots.txt that allows all crawling and references your sitemap is sufficient. For WordPress sites, blocking admin and system directories is appropriate. For e-commerce sites, blocking cart, checkout, and faceted navigation URLs conserves crawl budget.
The most important robots.txt practices: check it regularly to ensure no accidental blocks exist, never use "Disallow: /" on production, use noindex tags (not robots.txt) when you want to prevent indexing of crawlable pages, and include your sitemap URL in the file for easy discovery.
At Scalify, robots.txt configuration is part of every website launch checklist — verified correct before the site goes live, and reviewed as part of any significant site update.
Key Takeaways and Next Steps
The principles and data in this guide reflect what actually works in professional web development and digital marketing in 2026 — not theoretical best practices but measured, documented outcomes from implementations at scale. The gap between knowing these principles and benefiting from them is always execution: the businesses that act on what they read, implement changes systematically, and measure the results consistently outperform those who consume information without converting it to action.
For any improvement described in this guide, the implementation sequence that produces the best outcomes: assess your current situation against the benchmarks provided, identify the 2–3 highest-impact improvements specific to your situation, implement them with measurement tracking in place, evaluate results after 30–60 days, and plan the next iteration based on what you learned. This cycle — assess, prioritize, implement, measure, iterate — is the operational foundation of continuous improvement that compounds into significant competitive advantage over the 12–24 month horizon.
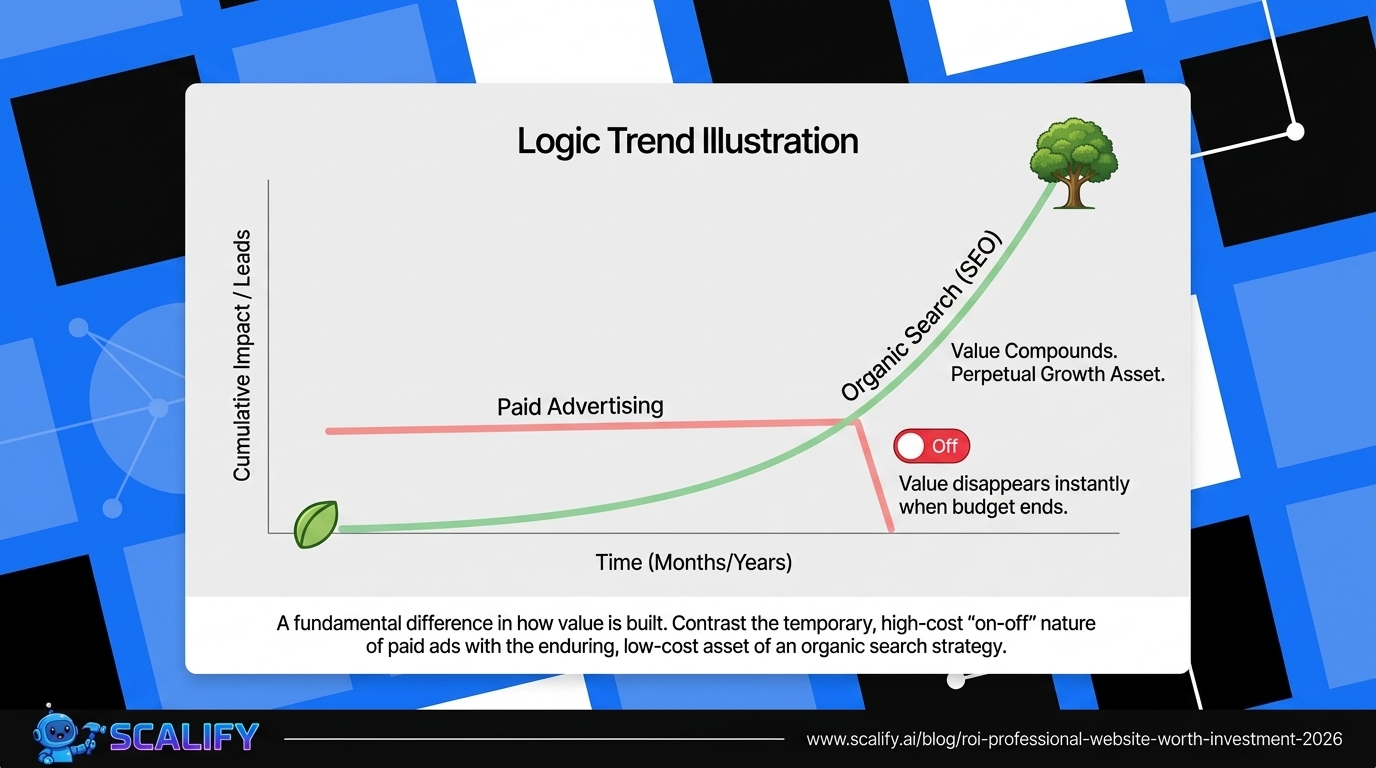
The compounding returns from consistent web presence investment are not linear: a website that improves slightly each month accumulates to dramatic improvements over a year, and those improvements multiply with each other. Faster load times improve both search rankings and conversion rates simultaneously. Better content attracts backlinks that improve rankings that attract more traffic. More testimonials build trust that improves conversion rates that improve revenue that funds more investment. The interconnected nature of website performance means that each improvement amplifies the value of every other improvement — making the decision to invest consistently, across multiple dimensions simultaneously, the highest-ROI approach to digital marketing available to most businesses.
At Scalify, every website we build reflects these principles — technically optimized, conversion-focused, SEO-ready, and designed to compound in value over time as content, backlinks, and organic authority accumulate on the strong foundation we deliver in 10 business days.


















.jpeg)

.jpeg)











78 SW 7th St, Miami, FL 33130


